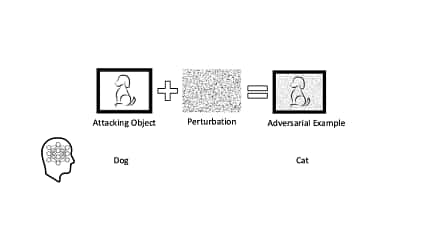
بدلیل کمبود دیتا و هزینه بر بودن برچسب زدن برای دادگان در تسکهای supervised یکی از عملیات بسیار پرکاربرد افزایش دیتاست. بسته به دادگان آموزش می توانیم این عملیات را انجام دهیم؛ برای مثال، اگر تسک object recognition بود، می توان تصاویر را shift داد یا کمی درجه چرخش را تغییر داد. به عنوان مثالی دیگر، برای تسکهای مربوط به صوت، می توان به دیتا، نویزهای متفاوت اعمال کرد. خوبی افزایش دیتا این است که دیتای آموزش را زیاد می کند و خطر بیش برازش کم می شود اما با این حال یکسری اشتباهات رایج وجود دارد که سعی می کنیم بررسی کنیم.
-
افزایش دیتا باید منطقی باشد؛ یعنی اینکه به این شکل کار نکنید که دادگان هر کلاس را به یک باره ده برابر کنید. این کار ممکن است چندان مفید نباشد. علت اصلی این است که شما وقتی با روشهای مرسوم، مثلا translation، دادگانتان را افزایش می دهید، information چندانی به مجموعه دادگان اضافه نمی کنید. درست است که داده اضافه می شود ولی اطلاعات جدید خیلی کمی اضافه می شود. وقتی خیلی داده زیاد می کنید، فرآیند آموزش بسیار هزینه بر می شود.
-
با افزایش دیتا، مشکلاتی مثل عدم وجود داده برای view point های متفاوت حل نمی شود. با یک مثال توضیح می دهیم. شما اگر تصویر تمام رخ و نیم رخ داشته باشید، با میانگین گیری نمی توانید تصویر سه رخ داشته باشید. به عبارتی دیگر، بدست آوردن تصویر سه رخ به صورت خطی انجام پذیر نیست.
-
هر روشی برای افزایش داده مناسب نیست. بسته به label لازم است تصمیم گیری شود. شما می توانید تصویر یک خودکار را بچرخانید ولی چرخشی که باعث می شود خطای بیز زیاد شود و خود انسان دچار اشکال شود، مناسب نیست؛ بنابراین، وقتی تعداد برچسبهای تسکتان زیاد است، به دقت کلاسها را بررسی کنید.
-
توزیع دادگان را تغییر ندهید. اشتباه رایجی که وجود دارد این است که خیلی ها فکر می کنند اگر دو کلاس بالانس نیستند لازم است که با افزیش دیتا، بالانس شوند. این کار بسیار خطرناک است. با این کار prior ها را به هم می ریزیم. فرض کنید می خواهیم در تصویر ورودی به دنبال ماشین باشیم. در تصاویر جاده که برای 20 سال قبل بوده اند، خودروها توزیعشان با الان متفاوت بوده اند. اگر با افزایش دیتا این توزیع ها را به هم بریزیم، نباید توقع داشته باشیم نتیجه خوبی بگیریم. توزیع داده باید واقعی باشد.