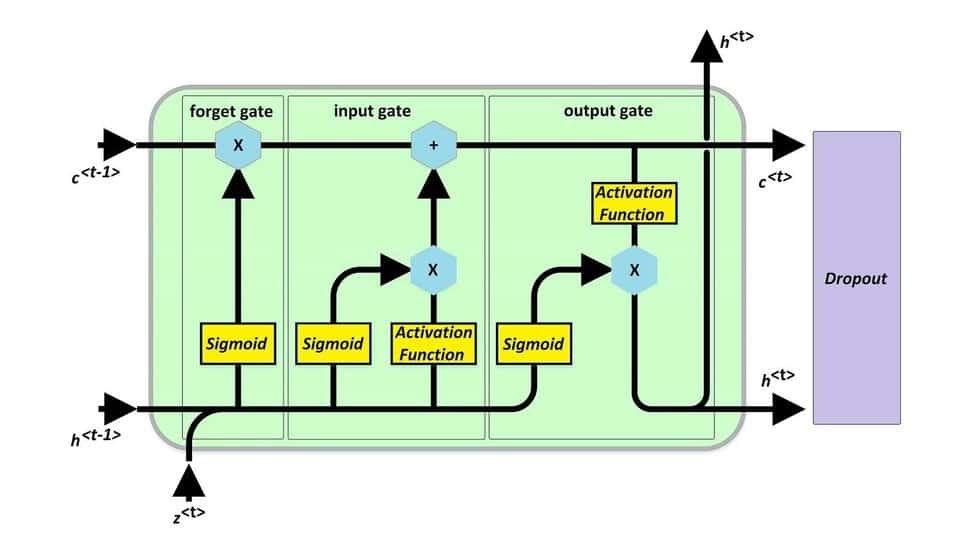
یکی از موثرترین راه ها برای جلوگیری از overfit شدن، استفاده از dropout در شبکه های عصبی است؛ با این حال، در شبکه های LSTM استفاده از این روش چندان توصیه نمی شود. اگر به صورت ساده انگارانه نگاه کنیم، هر شبکه LSTM به این شکل است که یک لایه به شدت غیر خطی است که همانند یک لایه dense است ولی با تفاوت های پایین:
- همه داده را به صورت یکجا دریافت نمی کند و پله پله روی ورودی حرکت می کند.
- از مرحله قبل ورودی دریافت می کند ولی اتصالات به صورت dense است.
- دارای گیت است که سبب می شود قدرت حافظه داشته باشد.
با دانستن این موارد، معلوم می شود که تعداد لایه های ما خیلی کم است که بخواهیم از dropout در شبکه LSTM استفاده کنیم؛ به عبارتی، تعداد نورونها خیلی محدود است و با drop کردن، اطلاعات خیلی زیادی از بین می روند. توصیه ای که می کنیم این است که سعی کنید از روشهای L1/L2 برای جلوگیری از overfit شدن استفاده کنید. ولی اینجا یک مشکلی وجود دارد. اگر از بهینه سازی مثلِ Adam استفاده کنید، چندان عملکرد بهبود پیدا نمی کند. بهتر است از روشهای بهینه سازی AdamW، SGD یا SGDW استفاده کنید.