
یکی از مسایلی که لازم است حتما در یادگیری عمیق لحاظ شود این است که در حین آموزش لازم است داده ها را shuffle کرد. علت این موضوع این است که داده ها وابستگی نداشته باشند و به اصطلاح i.i.d باشند. خوبی این موضوع این است که تابع هزینه ای که در هر iteration با minibatch کنونی تقریب می زنیم به خاطر داده های تصادفی، به شکل های اشتباه در نمی آید و جهت گیری هایی که سبب وابستگی داده ها است را پیدا نمی کند. اما یک دلیل دیگر نیز وجود دارد که با توجه به این دلیل، shuffle کردن داده ها حتما لازم است صورت گیرد. حتما شکل تابع هزینه را دیده اید که حاصل جمع خطا ها روی تک تک داده ها است؛ برای مثال log loss به این شکل است که شما جمع یکسری ترمِ لگاریتمی را دارید. خود این تابع هزینه با فرض i.i.d بودن داده ها بدست می آید. برای توضیح دادن ساده این موضوع به این شکل کار می کنیم که اگر بخواهیم احتمال رخ داد یک مجموعه دادگان را بررسی کنیم باید احتمال (P(x1, x2, ..., xn را پیدا کنیم ولی چون فرض می کنیم داده ها مستقل هستند با i.i.d پس حاصل احتمال ذکر شده به صورت ضرب تک تک احتمال داده ها قابل پیدا کردن است. اصطلاحا توزیع joint را به marginalها تبدیل کردیم. با یک لگاریتم گیری هم ضرب ها به جمع تبدیل می شوند.
دلیلی دیگر برای درهم ریختن داده ها

نوشته شده بوسیله:
کامران پناهی

کارشناسی ارشد هوش مصنوعی
علاقه مند به یادگیری عمیق
مطالب مشابه




مقالات
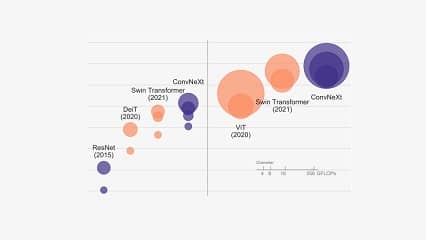
شناختِ مناسب از شبکه به صورت کلی در تمامی پروژه های هوش مصنوعی، چه دانشگاهی …
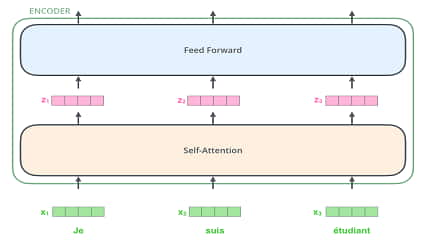
پیش از این به ایده ترنزفرمرها اشاره کرده بودیم. در این سلسله نوشتار قصد بیان …
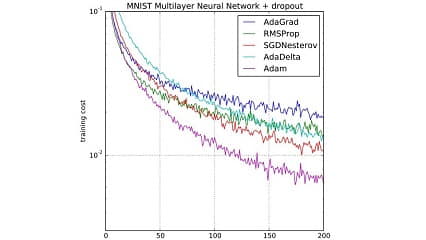
یکی از مسائلی که معمولا در پروژه های تجاری به درستی رعایت نمی شود، استفاده …

پیش از این در مورد [group theory](https://biasvariance.net/articles/pi8d5/introducing-group-theory-and-deep-learning/) صحبت کرده بودیم. در این پست در مورد …
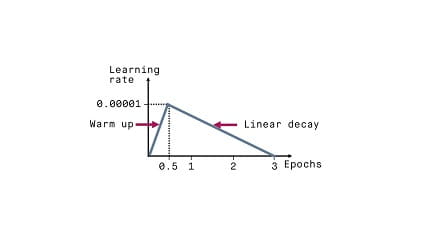
در آموزش شبکه های عصبی، learning rate یکی از مهمترین هایپرپارامترهایی است که لازم است …

دوره های آموزشی

Tensorflow یکی از محبوبترین کتابخانههای شبکههای عصبی است. بسیاری از شرکتهای بزرگ که در حوزهی …

حتما دیده اید که کتابخانه هایی مثل Pytorch یا Tensorflow هم در سایتشان، هم در …
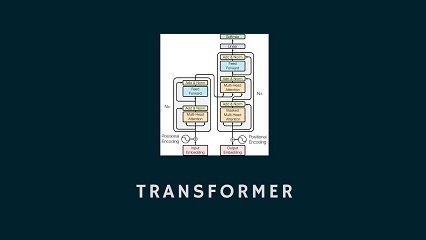
معماری تبدیلکننده، یک معماری شبکهی عصبی و یادگیری عمیق است که در سال 2017 ارایه …

یادگیری عمیق گونهای از الگوریتمهای یادگیری ماشین است که وابسته به انجام تعداد زیادی محاسبه …

زبان پایتون در چند سال اخیر به زبانی پرطرفدار تبدیل شده است. یکی از دلایل …