برای سالها، شبکه های عصبی بازگشتی، راه حل متخصصین حوزه شبکه های عصبی برای دادگان temporal بود که به صورت sequential بودند. ایده اولیه، استفاده از شبکه های ساده عصبی بود که در time step های پشت سر هم، stepهای ورودی در کنار حاصل محاسبات مراحل قبل را به عنوان ورودی قبول کنند. ولی بدلیل مشکلات این شبکه ها، مدلهای مبتنی بر حافظه نظیر LSTM ها و extensionهایش ارایه شدند. با این حال، شبکه های بازگشتی به صورت کلی ضعفهایی دارند که به تعدادی از آنها اشاره می کنیم.
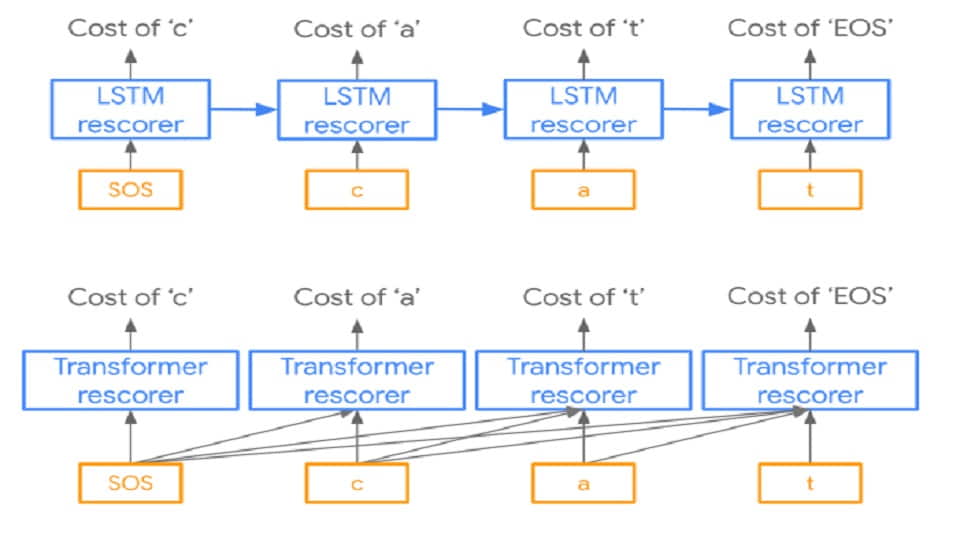
- تعداد محاسبات این شبکه ها بالاست. حتما در کدها دیده اید که تعداد LSTM Cell ها به ندرت عددی بیشتر از 512 است. علت زیاد بودن محاسبات این است که یکسری کار تکراری باید مدام برای فقط یک داده انجام شد که ماهیت سری زمانی دارد و این کارها را نمی توان به صورت موازی پیش برد؛ زیرا این شبکه از مرحله زمانی قبل نیاز به اطلاعات دارد.
- فرآیند آموزش طولانی است. به این دلیل که ترتیب در داده ها مهم است، شبکه باید ترتیب را لحاظ کند. این مسئله سبب می شود که اگر forward و backward pass را باز کنیم، با دنباله های بسیار طولانی از عملیات روبه رو شویم که قابلیت موازی سازی را هم ندارند. به همین دلیل، خیلی ها به فکر عمیق کردن LSTM ها نمی افتند.
- این شبکه ها در به خاطر سپردن چند چیز به صورت همزمان مشکل دارند.
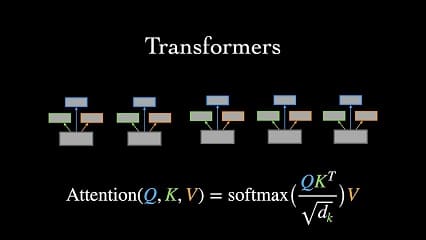
در literature برای اینکه تقریبا سعی شود از مشکلات RNN ها عبور کرد، مدل های مبتنی بر Attention ارایه شدند. در این مدلها سعی شده تا با کمک مفهوم weight sharing که در CNN ها قبلا جواب پس داده، در زمینه داده های temporal کار کرد. با همین ایده ساده weight sharing و ضرب داخلی که میزان شباهت را بیان می کند، انقلابی در NLP و تسکهای مربوط به دادگان temporal ایجاد شد.
شاید تا به امروز مقالات مربوط به attention را پیاده سازی کرده باشید، و تعجب کرده باشید که چرا ماتریس وزن را روی قسمت های ورودی به نوعی حرکت می دهیم. اگر با دید MLP ها نگاه کنیم، این کار کمی عجیب است. با این حال، همانطور که ذکر شد، ایده این کار از weight sharing می آید. با کمک weight sharing می توان موازی سازی داشت، و ساختارهای مشابه تکرار شونده در طول سیگنال ورودی را می توان به راحتی پیدا کرد.