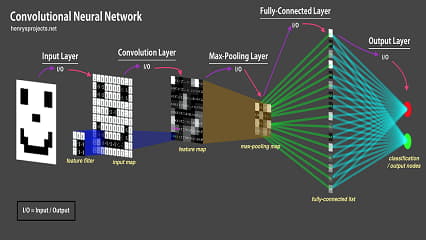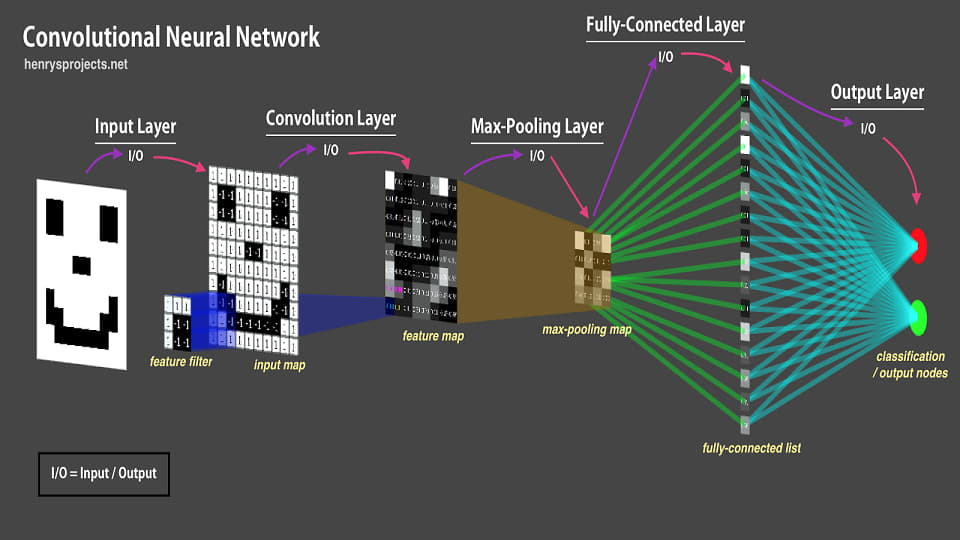
یکی از نقاط ضعف شبکه های کانولوشنی، قدرت تعمیم یا قدرت generalization آنهاست. به این شکل که اگر اعضای یک کلاس را در زمان آموزش فقط به یک حالت دیده باشند، در زمان تست هم فقط می توانند به همان شکل واکنش دهند؛ به عنوان مثالی ساده، اگر شبکه ای کانولوشنی صورت انسان را فقط به صورت نیم رخ و تمام رخ دیده باشد در زمان آموزش، نمی تواند عملکرد مناسبی داشته باشد اگر در زمان تست تصویر سه رخ را بگیرید. یکی از مواردی که مرسوم است در فرآیند آموزش شبکه های کانولوشنی، استفاده از data augmentation است. به این صورت که سعی می شود روی دادگان آموزش transfrom های متفاوت زده شود تا شبکه، دادگان آموزش را در حالات مختلف ببیند. در این حالت، اگر به فرض در دادگان فقط کشتی هایی دیده می شود که از چپ به راست حرکت می کنند، می توان با افزایش داده زاویه کشتی، جهت حرکت و ... را تغییر داد تا در نهایت قدرت تعمیم مدل افزایش پیدا کند. با این وجود، تبدیلاتی که اعمال می کنیم خیلی محدود است. تبدیلاتی مانند rotation،translation و scale تبدیلات مناسبی هستند ولی با این وجود محدودیت بزرگی دارند. اگر ما روی تصاویر نیم رخ، و تمام رخ تبدیلات خطی مانند آنهایی که ذکر کردیم را بزنیم، همچنان تصویر سه رخ نخواهیم داشت. پس حتی data augmentation هم نمی تواند خیلی از ضعف ها رو پوشش دهد. نکته کلیدی که وجود دارد این است که این موضوع ضعف ذاتی شبکه های کانولوشنی است. شما ممکن است از LeNet5 که شبکه ای بسیار بدوی است به سمت استفاده از ورژن های بالای ResNet بروید که قدرت یادگیری خیلی بالا و محاسبات متعادلی دارند ولی همچنان ضعف ذکر شده وجود دارد. می توان به این شکل گفت که شبکه های کانولوشنی عملکرد مناسبی برای قدرت تعمیم روی viewpoint های متفاوت ندارند.
Viewpoint Invariant
فرض کنید که تصویری از یک ماشین دارید و روی آن data augmentation می زنید. با این حال شما از viewpoint های متفاوت تصویر نخواهید داشت؛ یعنی اینکه اگر دوربین ثابت باشد و خود ماشین بچرخد، در این صورت دیتایی به این شکل ندارید. این موضوعی بود که سالها ذهن افراد زیادی را درگیر کرده بود. راه حلی که در literature وجود دارد شبکه های کپسولی است؛ برای شرح ساده این نوع شبکه ها، تصور کنید که شما در حال کار با نرم افزاری مثل 3d max هستید. در این حالت، شما اگر بخواهید یک جسمی را بزرگ یا کوچک کنید، لازم است برداری که نماینده آن جسم است را تغییر دهید. برای مثال فرض کنید، یک ورودی بیانگر طول، یکی بیانگر عرض و ... باشند. در این حالت، شما با تغییر المانهای این بردار مقداردهی، جزییات جسم را تغییر می دهید و قسمت های مختلف آن را کوچک و بزرگ می کنید. حال به صورت خیلی ساده انگارانه، فرض کنید که یکی از این المانها مربوط به چرخش باشد. در این صورت شما با تغییر عدد یکی از بعدهای بردار، میزان چرخش را تعیین می کنید. وقتی با شبکه های کپسولی کار می کنیم، سعی می کنیم با کپسولها به عنوان building block های شبکه عصبی کار کنیم و دیگر به صورت نورن به نورن شبکه را فرض نمی کنیم. در این حالت، قسمتهای مختلف و اجزای مختلف، کپسول خاص خودشان را خواهند داشت و هر کپسول بیانگر بردار مقداردهی است که تشبیهش را ذکر کردیم. در این صورت شبکه خیلی ساده تر از شبکه های کانولوشنی می تواند روی viewpoint های متفاوت خوب کار کند.
تغییر ناپذیر با جابه جایی؟!
حتما شنیده اید که شبکه های کانولوشنی نسبت به translation یا جابه جایی قابلیت تعمیم دارند. این یک حرف غیر دقیق است و باوری است نه چندان درست اگر فرضیات را لحاظ نکنیم. منشا این نگاه در این است که با استفاده از لایه پولینگ، محل دقیق وجود یا عدم وجود را از بین می بریم و در طول شبکه که چندین بار لایه پولینگ را اعمال می کنیم، اطلاعاتِ محل دقیق اشیا از ببین می رود. تا اینجا درست است و به همین سبب اگر اشیا در زمان تست کمی جابه جا شوند نسبت به آن چیزی که در زمان آموزش بوده اند مشکلی پیش نمی آید. ولی مشکل زمانی پیش می آید که شما فرض کنید این خاصیت جابه جایی را همیشه دارید. خیلی ساده اگر در زمان آموزش تمامی پرندگان در قسمت بالای تصویر باشند، در زمان تست اگر پرنده ای در پایین تصویر باشد و خیلی با بالا فاصله داشته باشد، شبکه خوب کار نمی کند. در هر حال ویژگی های استخراج شده در نهایت به لایه های تمام اتصال داده می شوند. اگر در قسمتی که مربوط به پایین تصویر است، هیچ وقت داده مناسب وجود نداشته، پس نمی توان توقع چندانی داشت. حال اینکه گفته می شود شبکه های کانولوشنی قدرت تعمیم خوب برای translation دارند، این حرف تا حدودی می تواند درست باشد، به شرطی که data augmentation داشته باشیم. لایه های پولینگ برای دستیابی به قدرت تعمیم برای جابه جایی به هیچ وجه کافی نیستند. توجه کنید که لایه های پولینگ اصلا مناسب نیستند و اینکه تا حدودی کار می کنند، یک فاجعه است. زیرا هر بار حداقل 75% اطلاعات را دور می ریزند.
پی نوشت
لازم به ذکر است که جابه جایی یا translation به خودیِ خود، یک تبدیل خطی نیست ولی می توان نقاط را به یک فضای بالاتر برد و در آن فضا تبدیل را به صورت خطی انجام داد تا در فضای ابتدایی translation داشته باشیم. بنابراین می توان translation را هم در کنار سایر تبدیلات خطی مثل rotation یا scale به راحتی با یک ماتریس بیان کرد و به سادگی قابلیت اعمال روی دیتاست را دارد.